- 文本数据
指不能参与算术运算的任何字符,也称为字符型数据。如英文字母、汉字、不作为数值使用的数字(以单引号开头)和其他可输入的字符。 - 文本数据的特点
- 半结构化
文本数据既不是完全无结构的也不是完全结构化的。例如文本可能包含结构字段,如标题、作者、出版日期、长度、分类等,也可能包含大量的非结构化的数据,如摘要和内容。 - 高维
文本向量的维数一般都可以高达上万维,一般的数据挖掘、数据检索的方法由于计算量过大或代价高昂而不具有可行性。 - 高数据量
一般的文本库中都会存在最少数千个文本样本,对这些文本进行预处理、编码、挖掘等处理的工作量是非常庞大的,因而手工方法一般是不可行的。 - 语义性
文本数据中存在着一词多义、多词一义,在时间和空间上的上下文相关等情况。
- 半结构化
为了迎合Pandas的发展模式,我们全部用string来操作字符串。
string与object的区别:
- 字符存取方法(string accessor methods):
string会返回相应数据的Nullable类型;
object会随缺失值的存在而改变返回类型。- 某些Series方法不能在string上使用。例如: Series.str.decode()。
因为存储的是字符串而不是字节- string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan
既然我们选择了string来操作字符串,那么我们遇到非string类型数据时,必须要先把数据转换为string类型。
string类型的转换分两步走:先转为str型object,再转为string类型
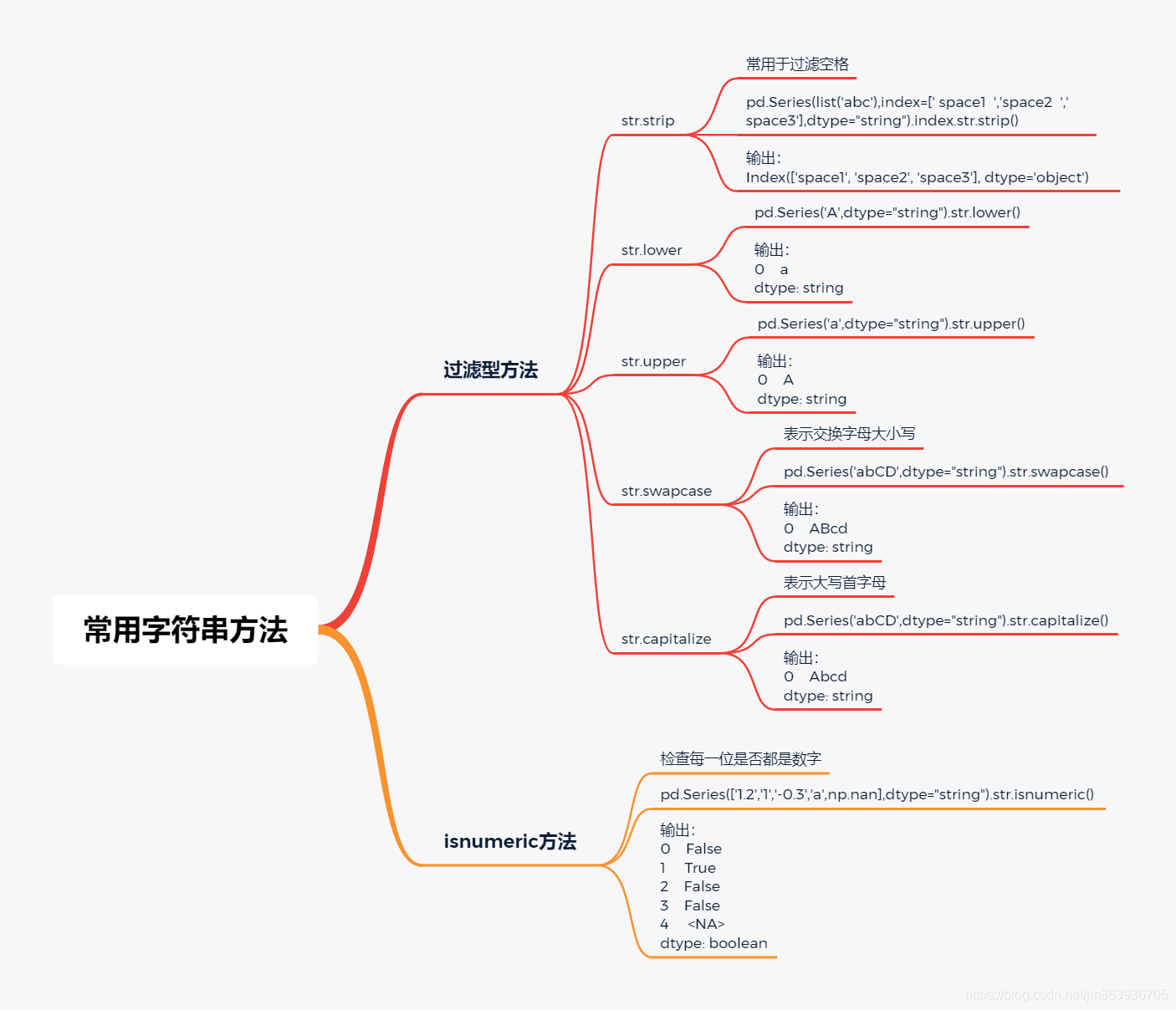
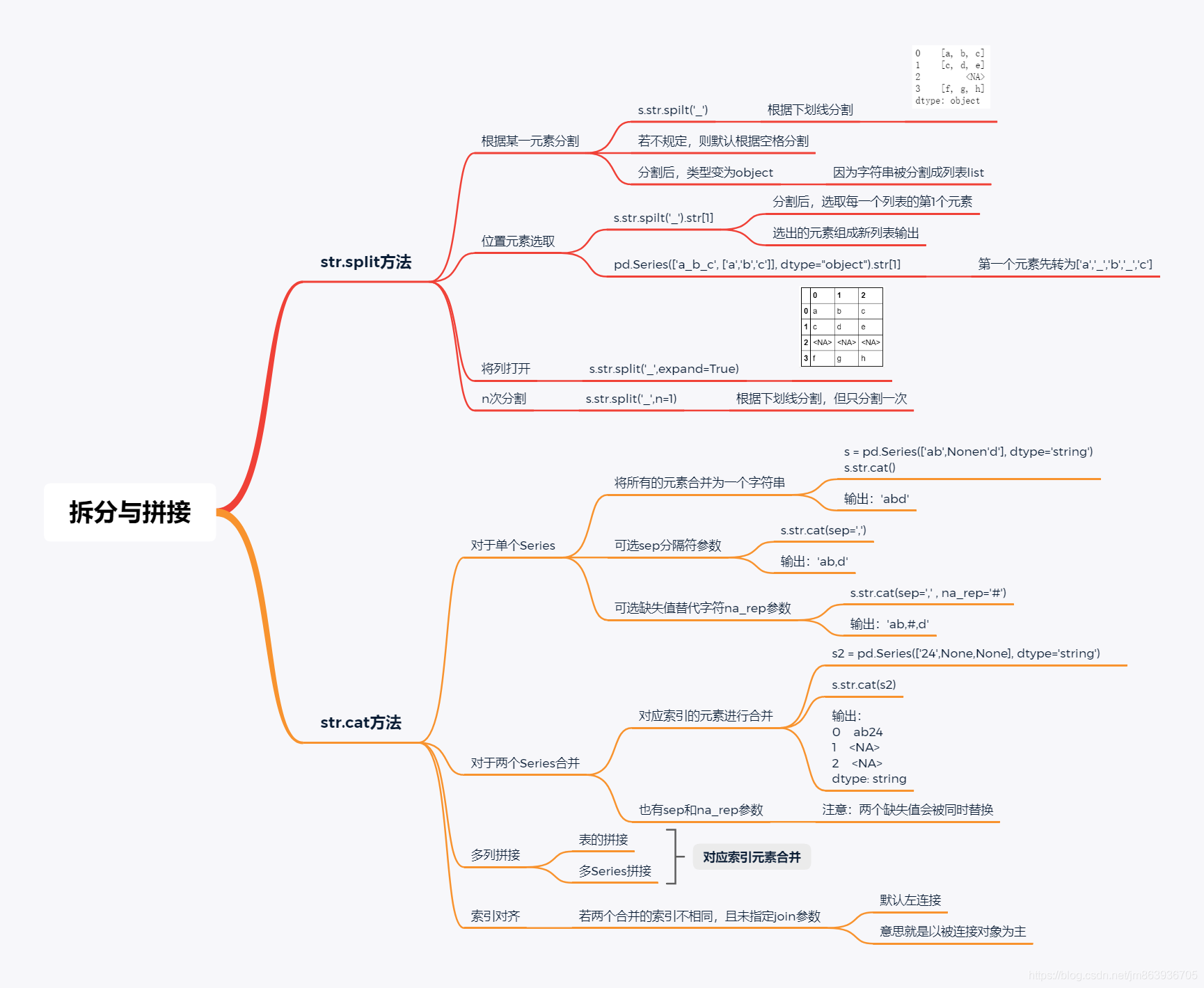
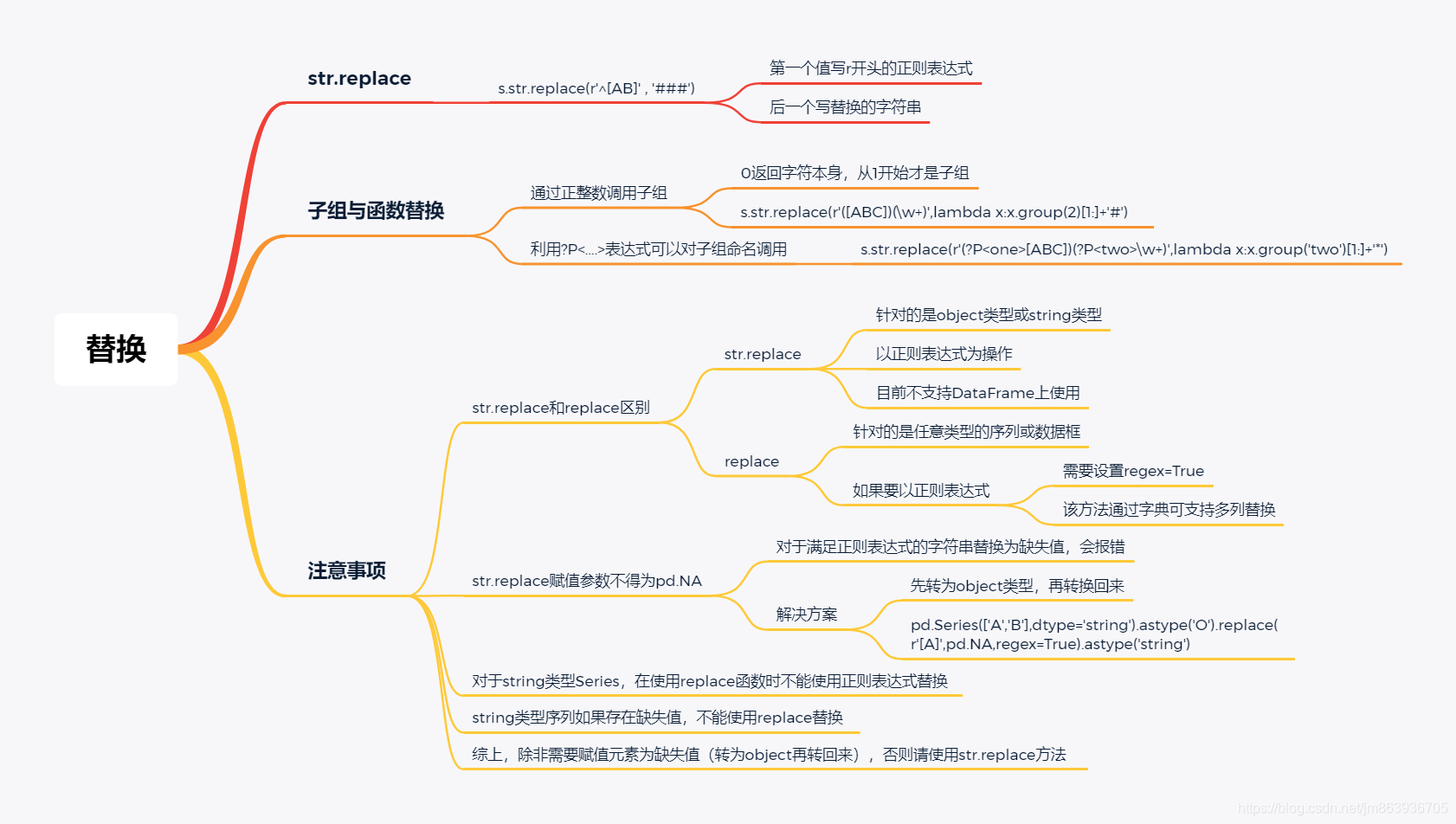
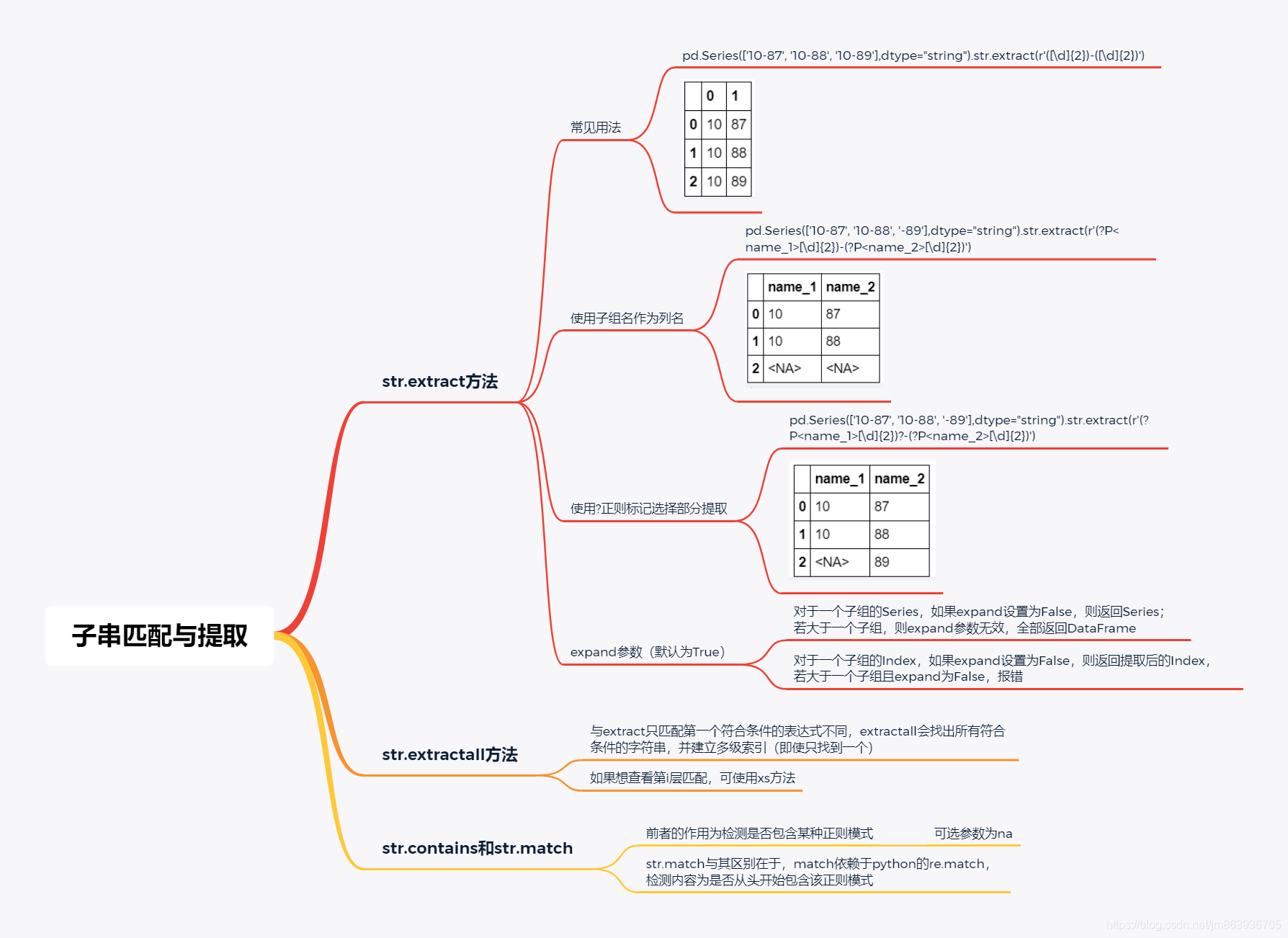
#以整型数据转换为string型举例,其它类型数据(如float型、bool型)的转换类似 pd.Series([1,2]).astype('str').astype('string') string基本语法包括拆分与拼接、替换、子串匹配与提取、过滤、isnumeric方法。
拆分与拼接
替换
子串匹配与提取
常用字符串方法